Physical Violations
Violations of physical laws, e.g., floating objects or unnatural trajectories.
An object hovers with no support.
ECCV 2026
A benchmark for evaluating Vision Language Models on precisely localizing and explaining errors in AI-generated videos: 1,600+ fine-grained, temporally localized error annotations across 6 categories and 3 difficulty levels.
1University of British Columbia 2Toyota Technological Institute at Chicago
Overview
As Text-to-Video models push toward higher realism, their artifacts become nuanced, fine-grained, and spatio-temporally localized. VLMs are increasingly used as automatic evaluators — but can they actually detect, localize, and explain these errors? Spotlight is a benchmark of 600 videos from state-of-the-art T2V models (Veo 3, Seedance, LTX-2), annotated with 1,600+ fine-grained error localizations across physics, semantics, and anatomy.
Our experiments reveal that current VLMs lag well behind humans — the best baselines trail human performance by nearly 2×, pointing to the need for more robust perception and hallucination mitigation.
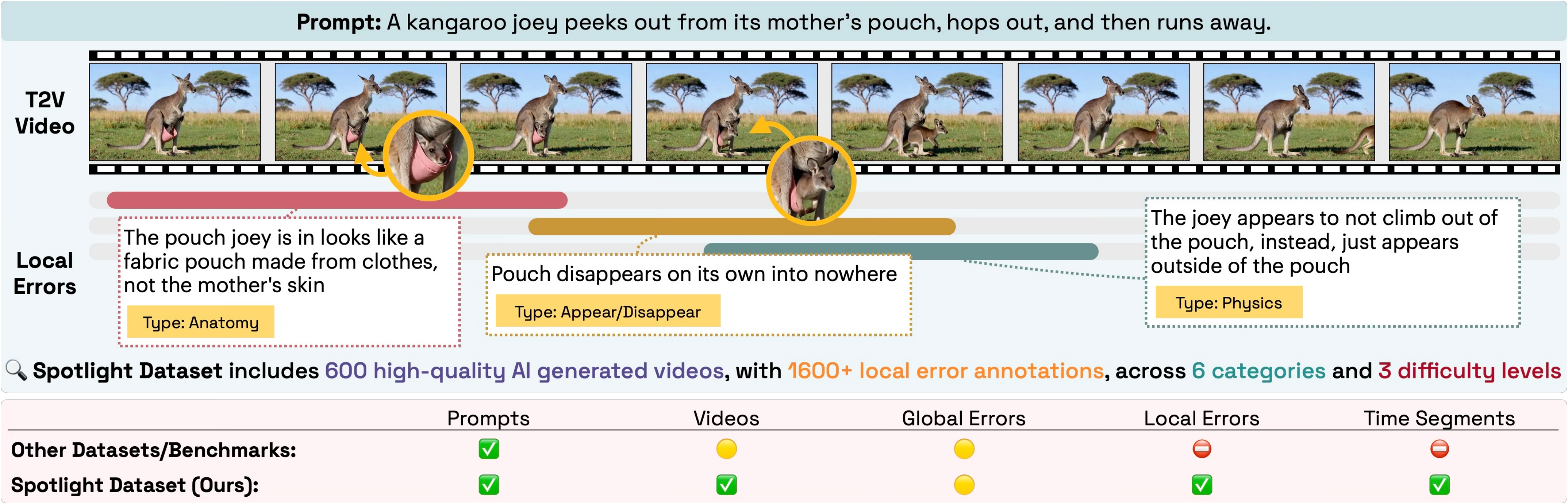
Examples
Real AI-generated clips, each carrying timestamped, categorized error annotations. Click a card to play the video and step through its localized errors on a timeline.
Taxonomy
Every annotation in Spotlight is tagged with one of six fine-grained error types, spanning the physics, semantics, and anatomy of a generated video.
Violations of physical laws, e.g., floating objects or unnatural trajectories.
An object hovers with no support.
Objects, people, or backgrounds appear or disappear unnaturally between frames.
“The white sheet of paper appears out of thin air.”
Unnatural motion such as objects passing through each other or jittery movement.
A hand clips through a solid table.
Failure to follow key elements or intent of the text prompt.
“Prompt says she is reading, but she scrolls too fast to be reading.”
Actions that cannot logically co-exist, or illogical story progression.
A glass shatters, then is whole again.
Impossible body shapes or joint movements; unrealistic morphing.
A limb bends against its joint.
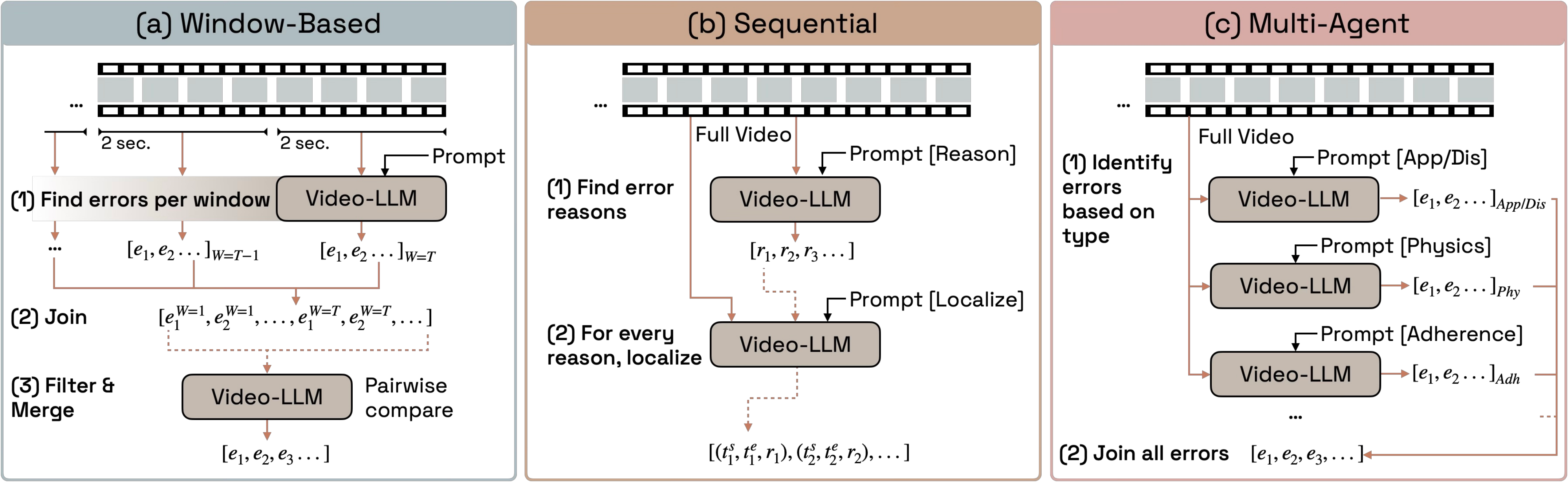
Method
We compare a model's predicted errors against ground-truth annotations with a pairwise-matching metric, then evaluate several inference-time baselines.
Score every predicted error against every ground-truth error to fill matrix F.
Keep only confident matches to build the binary match matrix.
Find the best one-to-one match pairs, then compute M and M%.

Find errors in short windows, then join, filter, and merge with pairwise comparison.
First reason about errors over the full video, then localize each one in a second pass.
Specialized agents identify errors by type (physics, anatomy, adherence…), then join all errors.
Videos by difficulty, stacked by T2V model. Click a model in the legend to toggle it.
Key result
Across both metrics, the strongest baselines fall far short of human annotators at localizing and explaining errors.
M(E, Ê)
M%(E, Ê)
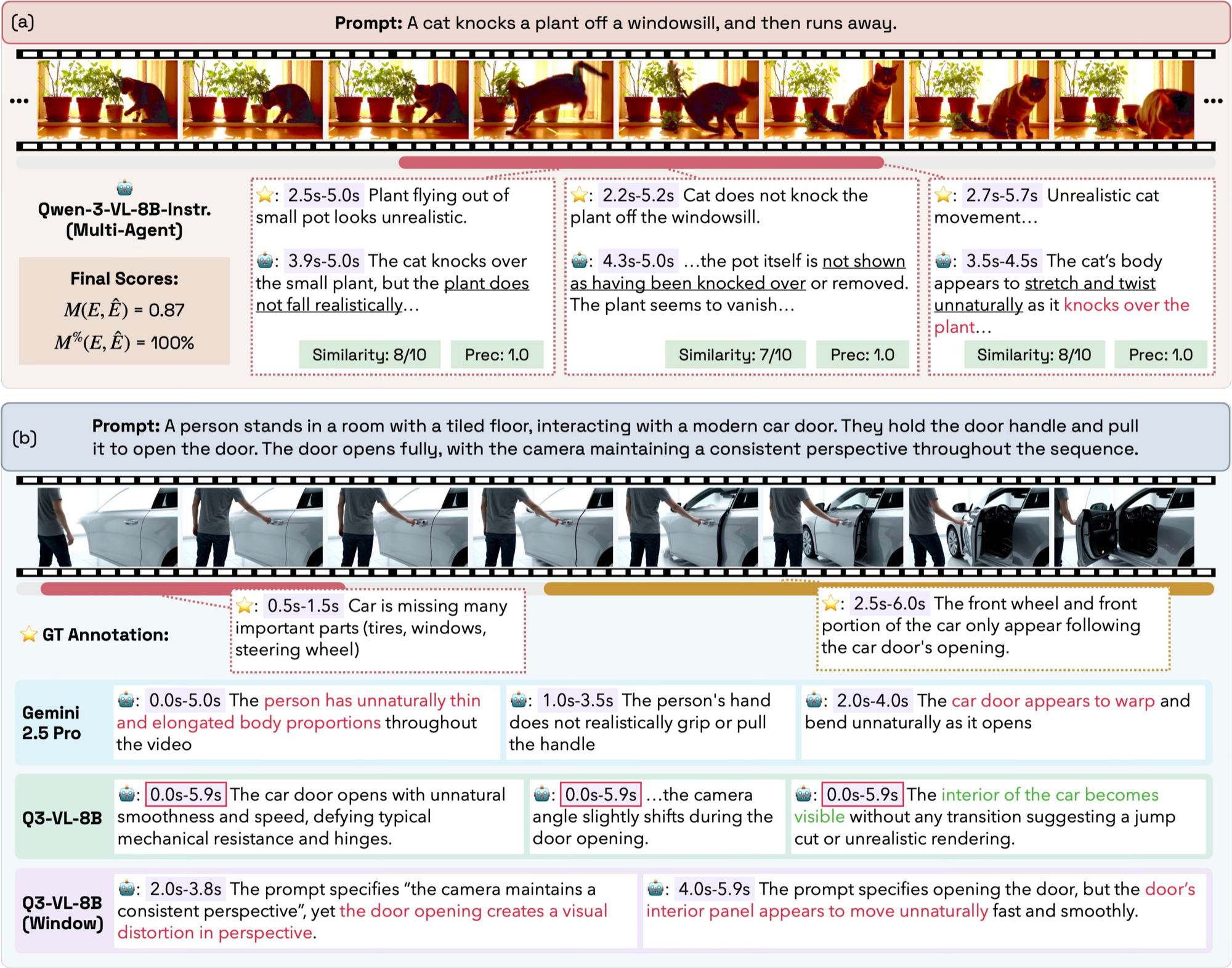
Error analysis
We categorized the failures of Gemini 2.5 Pro. Faulty perception and hallucination dominate — the model often misses what is visibly there, or invents errors that aren't.
Can't compare frames and misses what's visibly there — which leads to hallucinated errors.
Bad intuition for what is physically plausible.
Open-source models (Qwen3-VL) flag the whole clip as a single error.
Citation
@inproceedings{chinchure2026spotlight,
title = {Spotlight: Identifying and Localizing Video Generation Errors Using VLMs},
author = {Chinchure, Aditya and Ravi, Sahithya and Shukla, Pushkar and
Shwartz, Vered and Sigal, Leonid},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2026},
eprint = {2511.18102},
archivePrefix = {arXiv},
primaryClass = {cs.CV}
}